|
Yuwei An I'm an incoming CS PhD student at Princeton University, co-advised by Professor Ravi Netravali and Professor Tri Dao. I got my Master's Degree in Electrical and Computer Engineering from Carnegie Mellon University and my Bachelor's Degree from the Department of Computer Science and Technology, Tsinghua University. I am a contributor to SGLang working with Lianmin Zheng and Ying Sheng, and LMCache working with Junchen Jiang. Previously I worked closely with Professor Beidi Chen.
Email / CV / Github / X / Google Scholar |

|
Research InterestsMy primary research interest lies in Machine Learning Systems (MLSys). On the algorithmic side, I develop efficient LLM inference algorithms, including sparsity, parallel generation, and speculative decoding. On the system side, I design high-performance LLM serving systems, with work ranging across the full stack, including computation–I/O overlapping, scheduler design, Torch compilation, and kernel optimization. I do both research and engineering. |
News
|
Publications
Selected PaperList / Full PaperList. * denotes equal contribution.
|
Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
Xinyu Yang*, Yuwei An*, Hongyi Liu, Tianqi Chen, Beidi Chen NeurIPS 2025 Spotlight paper / project page |
|
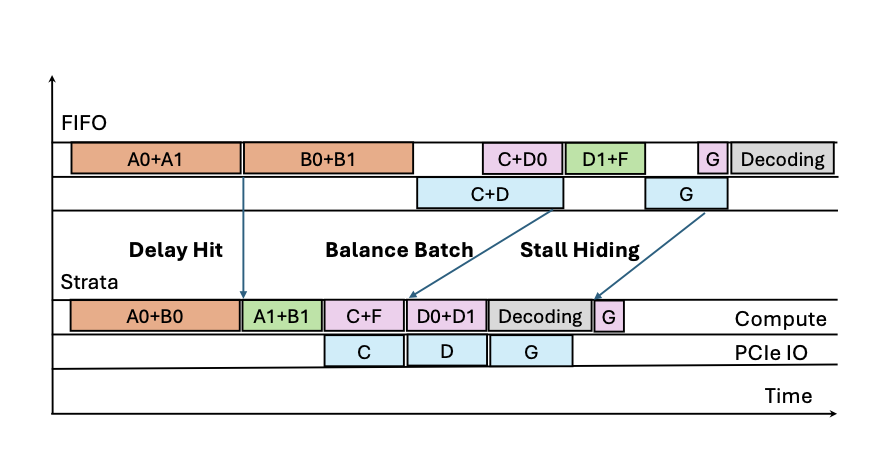
LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference
Yihua Cheng*, Yuhan Liu*, Jiayi Yao*, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, Junchen Jiang paper / project page |
|
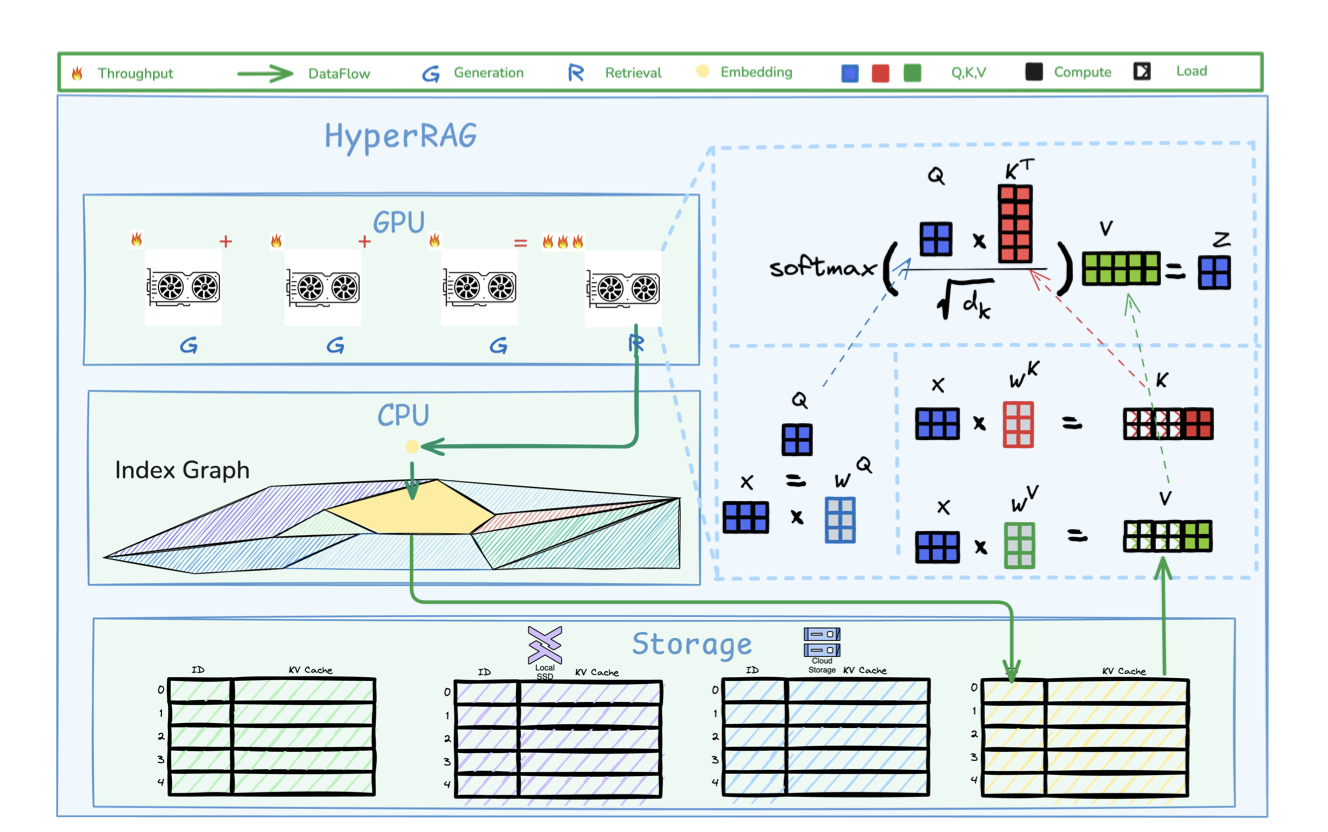
Strata: Hierarchical Context Caching for Long Context Language Model Serving
Zhiqiang Xie, Ziyi Xu, Mark Zhao, Yuwei An, Vikram Sharma Mailthody, Scott Mahlke, Michael Garland, Christos Kozyrakis OSDI 2026 paper |
|
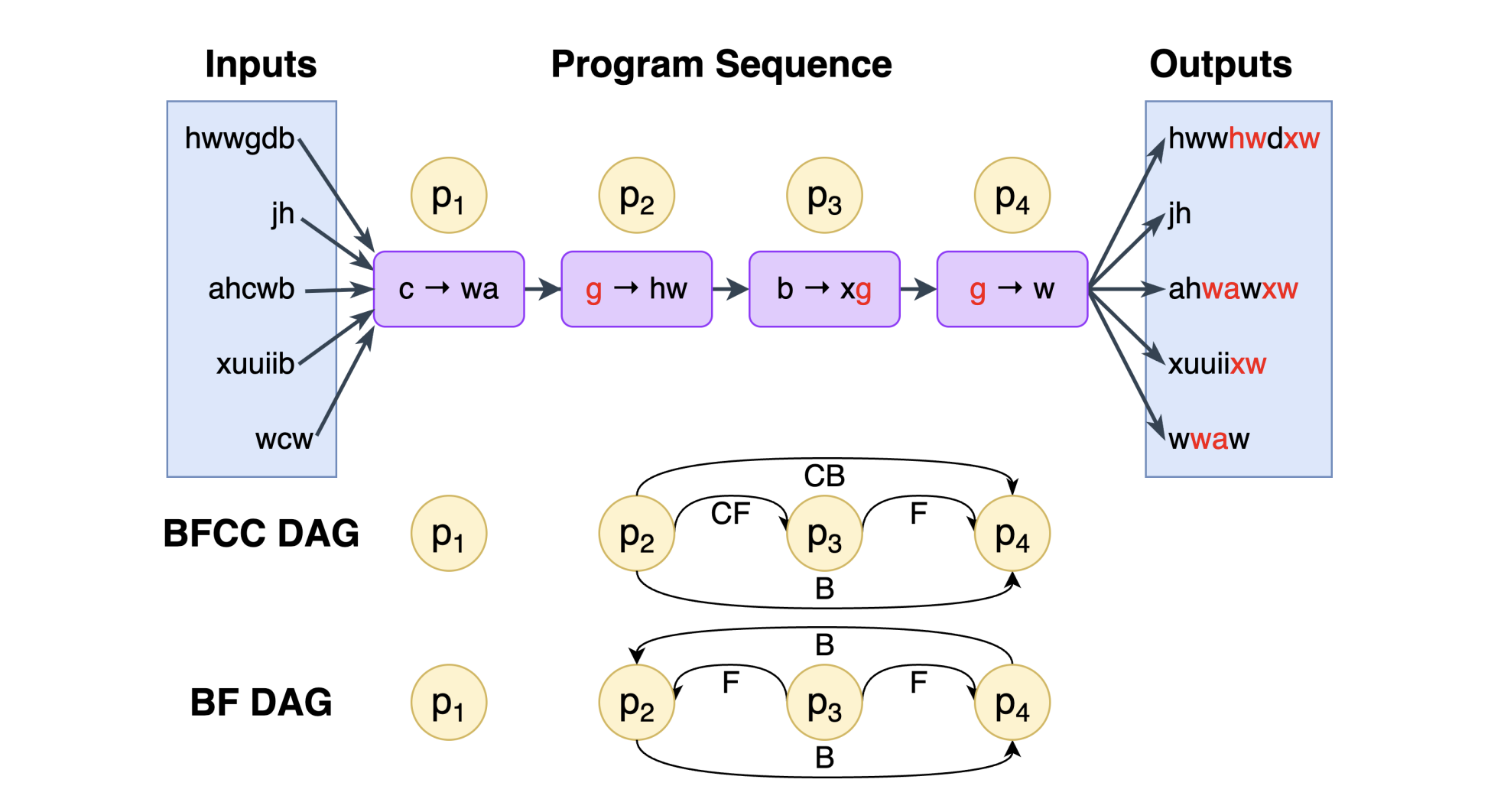
HyperRAG: Enhancing Quality-Efficiency Tradeoffs in Retrieval-Augmented Generation with Reranker KV-Cache Reuse
Yuwei An, Yihua Cheng, Seo Jin Park, Junchen Jiang paper |
|
PBEBench: A Multi-Step Programming by Examples Reasoning Benchmark inspired by Historical Linguistics
Atharva Naik, Prakam, Yash Mathur, Darsh Agrawal, Manav Kapadnis, Yuwei An, Clayton Marr, Carolyn Rose, David Mortensen ACL 2026 Findings paper |
|
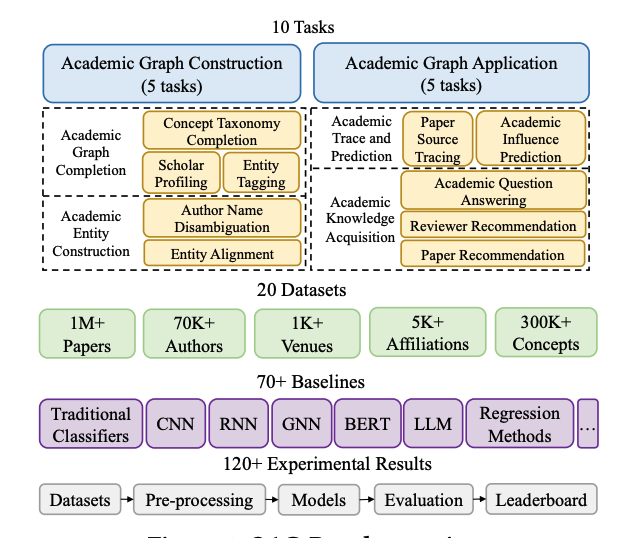
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Fanjin Zhang, Shijie Shi, Yifan Zhu, Bo Chen, Yukuo Cen, Jifan Yu, Yelin Chen, Lulu Wang, Qingfei Zhao, Yuqing Cheng, Tianyi Han, Yuwei An, Dan Zhang, Weng Lam Tam, Kun Cao, Yunhe Pang, Xinyu Guan, Huihui Yuan, Jian Song, Xiaoyan Li, Yuxiao Dong, Jie Tang KDD 2024 paper |
|
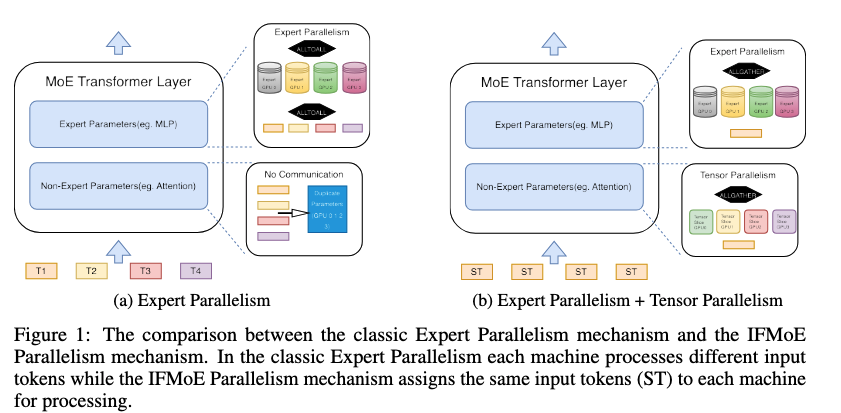
IFMoE: An Inference Framework Design for Fine-grained MoE
Yuwei An, Zhuoming Chen, Beidi Chen NeurIPS 2024 MLSys Workshop paper |
|
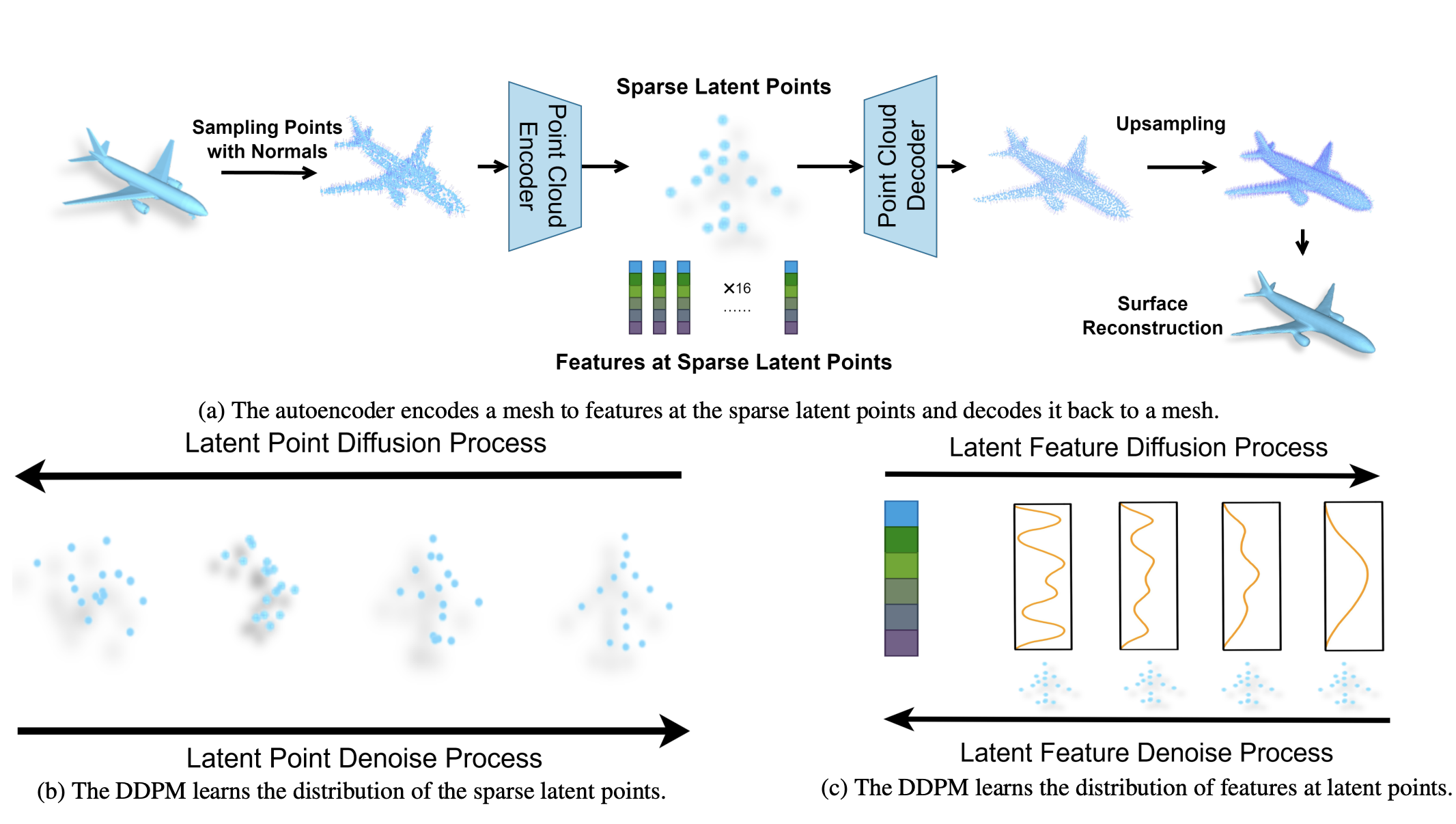
Controllable Mesh Generation Through Sparse Latent Point Diffusion Models
Zhaoyang Lyu*, Jinyi Wang*, Yuwei An, Ya Zhang, Dahua Lin, Bo Dai CVPR 2023 paper |
Open Source Projects |

|
SGLang
SGLang is a high-performance serving framework for large language models and vision-language models. Working on: Torch Compile Backend, Piecewise CudaGraph, HiCache. |

|
LMCache
LMCache is a LLM serving engine extension to reduce TTFT and increase throughput, especially under long-context scenarios. Working on: SGLang Support, Multi Process KV Engine. |
Teaching & Service |
|
Teaching Assistant: CMU 18-789 Deep Generative Modeling, Spring 2025 Tutorial: SIGCOMM 2025 — Networking for Stateful LLM Inference Conference Reviewer: CVPR, ICCV, ICLR |
|
This is the source code from Jon Barron. Thanks to him for sharing this beautiful template |